前言
MQ介绍
消息队列(Message Queue,MQ)是消息传递中间件解决方案的一个组件,旨在支持独立的应用和服务之间的信息交换。消息队列按发送顺序存储“消息”(由应用所创建、供其他应用使用的数据包),直到使用方应用能够处理它们为止。这些消息安全地等待接收方应用做好准备,因此,即使网络或接收方应用出现问题,消息队列中的消息也不会丢失。
这种称为异步消息传递的模式可防止数据丢失,并使系统能够在流程或连接失败时继续工作。这也使开发人员能够将流程与应用分离,确保它们的通信是独立的,而且由事件驱动,从而使架构更加可靠。
对于完全没有听说过MQ的读者,不妨设想这样一些典型的场景:
- 你的应用有不止一个程序在协同工作,他们分布在不同的机器、网络上,甚至采用了不同语言开发。
- 你的应用需要延迟处理一些数据。
- 你希望一些数据能够被妥善得到处理,也就是保证它一定会被处理而不会发生丢失。
- 你希望在程序之间实现类似广播的机制进行通信。
在诸如此类的场景中,我们需要在应用程序(一个服务端进程)之外实现各种五花八门的通信。我希望将这样的场景描述为为“一些程序在处理(不管是立刻还是稍后,一次还是多次)另外一些程序产生的数据,而且常常需要按照顺序处理”,在这里要处理的数据就可以视作“消息(Message)”,而用于存放这些消息、按照先来后到的顺序消费的容器就是一个“队列(Queue)”,所谓“消息队列”也不过是这样一个在“队列”里装“消息”的中间件。
消息队列的应用场景十分广泛,例如;
适当记忆可以作为八股的标准答案(
- 数据的异步通信,开发人员不需要考虑网络协议和远程调用的问题。
- 系统业务解耦,分布系统之间,不必直接强依赖。
- 消息数据入队出队,流量削峰。
- 跨平台跨语种的消息通讯。
- 可做缓冲等。
MQ的特性和设计
本节以Kafka为例介绍MQ的一般结构。通常来讲,MQ会涉及以下概念:
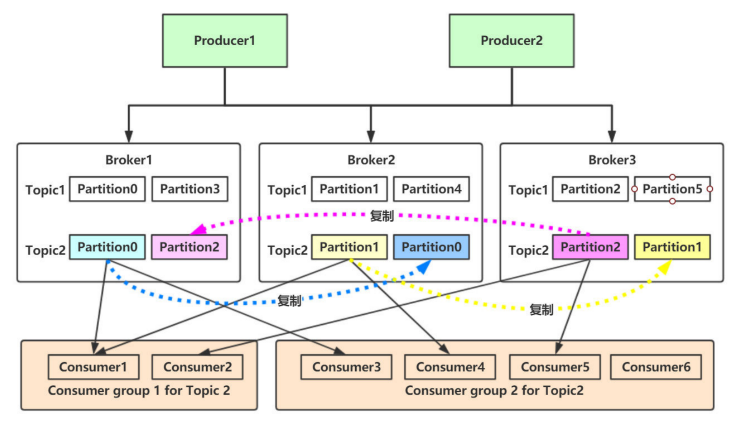
- Message:Kafka的数据单元称为消息。可以把消息看成是数据库里的一个“数据行”或一条“记录”。
- Topic:消息的类别,Kafka的消息是以topic为单位进行归类的。可以把topic看成是数据库里的一个“表”。
- Partition:分区,每个topic可以分为多个分区,每个分区是一个有序的队列,方便扩容。
需要注意在一个分区内的Message是有序的,然而,不同Partition之间无法保证有序。
- Replicas:副本,每个分区可以有多个副本,用于保证数据的可靠性。
- Producer:生产者,负责生产消息并发送到Kafka的Broker。默认情况下把消息均衡地分布到Topic的所有Partition上。
- Consumer:消费者,负责从Kafka的Broker上拉取消息并进行处理。
- ConsumerGroup:消费组保证每个分区只能被一个消费者使用,避免重复消费。如果群组内一个消费者失效,消费组里的其他消费者可以接管失效消费者的工作再平衡,重新分区。
- Broker:Kafka集群中的每个服务器节点称为Broker,连接生产者和消费者。Broker负责保存消息的偏移量、响应Consumer的拉取请求等。
以上便是Kafka的主要结构。可以看到,尽管Kafka的组件不算少,但工作过程还是比较清晰的。在Kafka中,Producer负责生产消息,Consumer负责消费消息,Broker负责保存消息,而Topic、Partition、Replicas、ConsumerGroup则是为了保证消息的可靠性和高可用性而设计的。
得益于各种设计,Kafka有一些显著的优点,此处略作总结以便记忆:
- 高吞吐量:单机每秒处理几十上百万的消息量。
- 零拷贝:减少内核态到用户态的拷贝,磁盘通过
sendfle实现 DMA 拷贝Socket buffer。 - 顺序读写:充分利用磁盘顺序读写的超高性能。
- 页缓存mmap:将磁盘文件映射到内存,用户通过修改内存就能修改磁盘文件。
- 高性能:单节点支持上千个客户端,并保证零停机和零数据丢失。
- 持久化:将消息持久化到磁盘。通过将数据持久化到硬盘以及replication防止数据丢失。
- 分布式系统,易扩展:所有的组件均为分布式的,无需停机即可扩展机器。
- 可靠性:Kafka是分布式,分区,复制和容错的。
- 客户端状态维护:消息被处理的状态是在Consumer端维护,当失败时能自动平衡。
几种常见的MQ
目前来看,Kafka、RabbitMQ、RocketMQ可以算是最主流的三个选择,而且三者的应用场景没有太大的交叉。我们大致可以这样认识三者:
- RocketMQ 定位于非日志的可靠消息传输(日志场景也OK)。作为阿里开源的项目,RocketMQ 在订单处理等业务领域凭借其特性(支持事务消息、顺序消息、消息回溯等)显得格外使用,但是从开源社区来看其生态属实一般。
- Kafka 是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。可以说,Kafka 是 MQ 中间件不折不扣的标准代表。
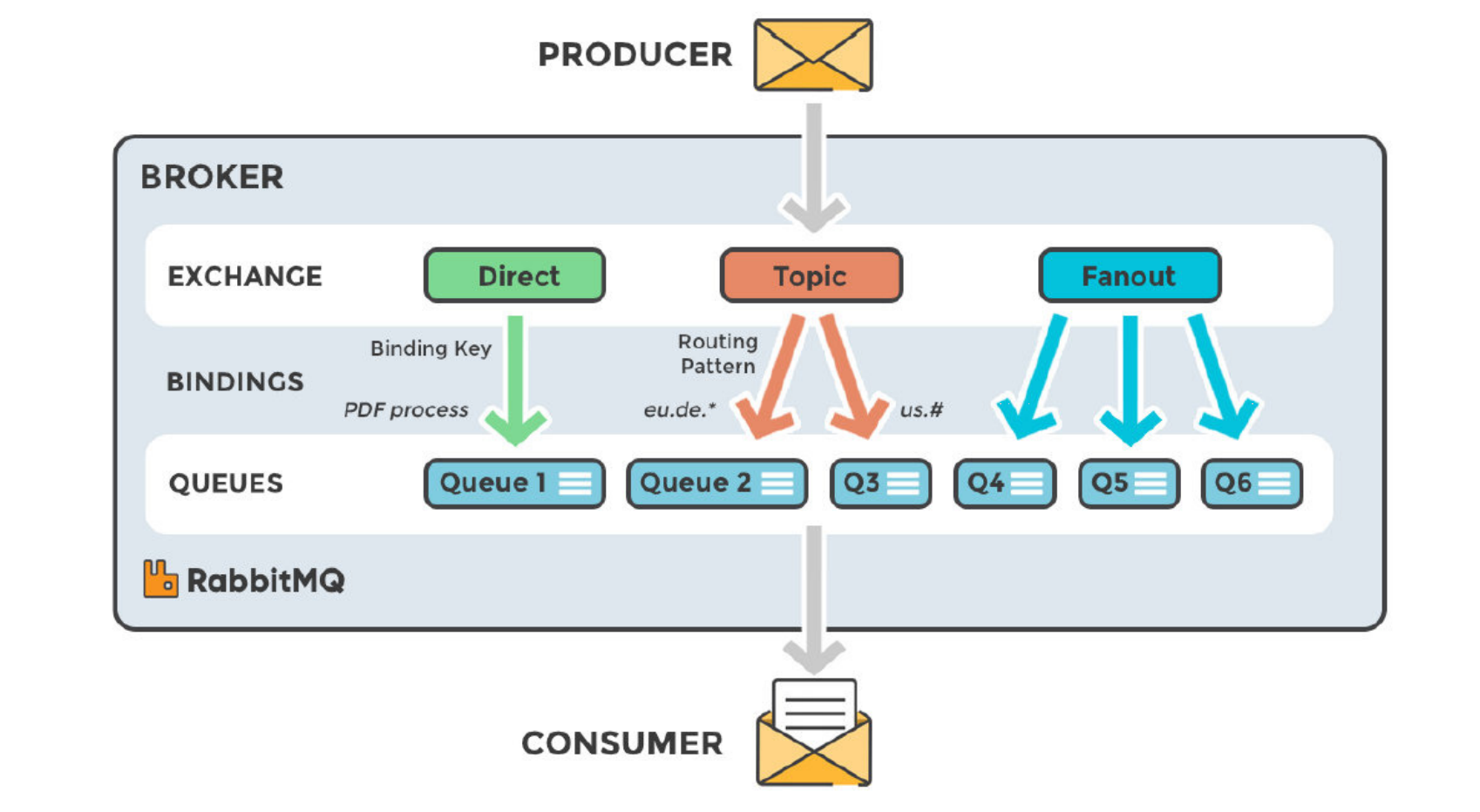
- RabbitMQ 是使用 Erlang 开发的开源消息队列系统,基于AMQP协议来实现。相比 Kafka,RabbitMQ 更加注重消息的可靠性,支持事务、持久化、集群等特性,适合对消息的可靠性要求较高的场景。
RabbitMQ开始是用在电信业务的可靠通信的,也是少有的几款支持AMQP协议的产品之一。RabbitMQ中,在生产者和队列之间有一个交换器模块。根据配置的路由规则,生产者发送的消息可以发送到不同的队列中。路由规则很灵活,还可以自己实现。相比 Kafka 和 RocketMQ,它的结构更简单一些(如下图所示),可以粗略看一眼作为对MQ的一个认识。
在具体指标上,下表可以作为一个参考:
| 特性 | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|
| 单机吞吐量 | 1w | 10w | 10w |
| 开发语言 | Erlang | Java | Java & Scala |
| 消息延迟 | 微妙 | 毫秒 | 毫秒 |
| 消息丢失 | 可能性很低 | 参数优化后可以0丢失 | 参数优化后可以0丢失 |
| 消费模式 | 推拉 | 推拉 | 拉取 |
| 主题数量对吞吐量的影响 | 没啥影响 | 几百上千个会有影响 | 几十上百个会有影响 |
| 可用性 | 主从 | 主从 | 分布式 |
Kafka快速体验
Kafka基本原理
生产环境特性
Kafka实现细节
经典问题
线上Rebalance
Q:因集群架构变动导致的消费组内重平衡,如果kafka集内节点较多,比如数百个,那重平衡可能会耗时导致数分钟到数小时,此时kafka基本处于不可用状态,对kafka的TPS影响极大。